

Machine Learning Workflow
The process of machine learning can be broken down into three easy-to-understand steps:
(1) Data processing
(2) Data modeling
(3) Deployment
It is very easy to understand the preceding three phases as shown in Figure 3-2.
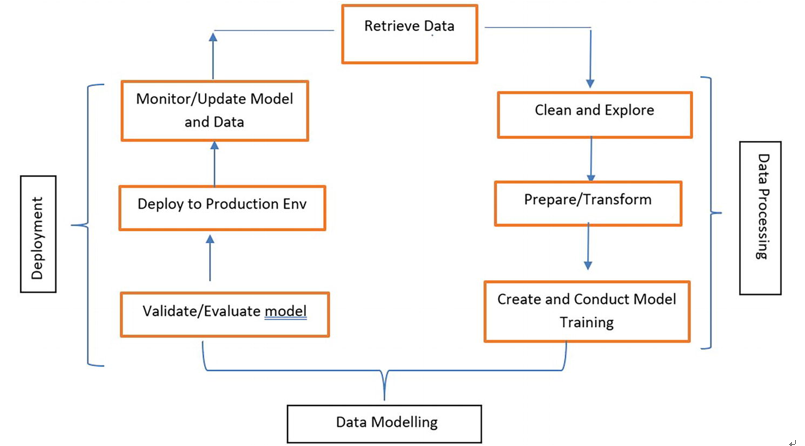
Figure 3-2Machine learning workflow
Data Processing
The whole point of data processing is to make a set of data more useful and relevant by processing it in different ways and getting it into a more desirable and informative shape by using machine learning algorithms, statistics, and mathematical modeling.
It is almost essential to state here that 80% of your problems are solved if you have been assigned or are working with a dataset that is already in good and relevant shape.
You can further divide data processing into three stages:
- Data collection: Collecting raw data from relevant and accurate sources so that the collection in question is usable and not irrelevant. The term “raw data” can refer to a variety of different things, such as monetary figures, website cookies, profit-and-loss statements of a company, user behavior, etc.
- Cleaning data: In this stage, the raw data collection is checked for possible errors, inadequacies, duplication, and miscalculations. All the unwanted data is removed so that the data can be prepared for the next stage of processing. Data cleaning is also known as data preparation because here the data is made ready for being used in further processes.
- Data processing: In this stage, the unprocessed data is put through a variety of data processing procedures, including those based on machine learning and artificial intelligence algorithms, in order to generate the result that was aimed for. This step might be different from one process to the next depending on the origin of the data that is being processed, as well as the purpose for which the output is going to be used.